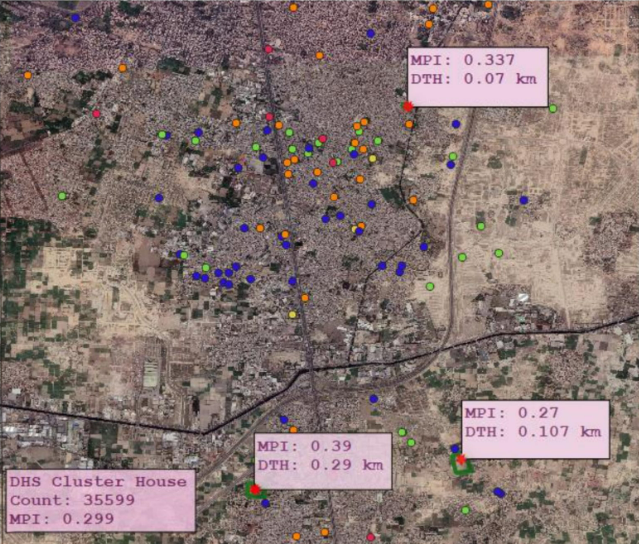
While income-based poverty represents a key factor influencing well-being and societal progress, there is a broader set of deprivations—relating to health, education and basic standards of living—that affect the lives and livelihoods of individuals and families. These directly affect people’s ability to break out of poverty. Many countries now measure multidimensional poverty alongside income-based poverty. The former is considered a broader definition of poverty. Under this broader definition of poverty, many more people come into… Continue reading
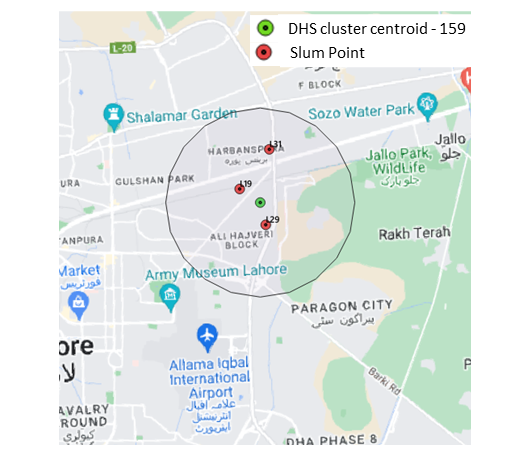
Our first blog in the series, “Comparing Deprivation: Slums vs. Demographic Health Survey Clusters in Lahore, Pakistan” takes into account Cluster-ID HV001-154. Continue reading
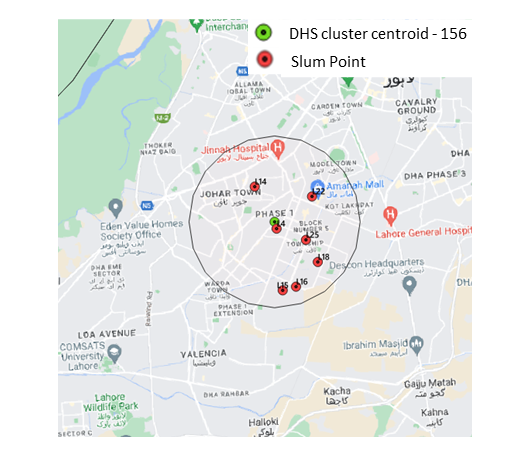
This second blog in the series offers a rigorous exploration of poverty’s complex facets within Lahore’s Cluster ID 156 and encompassed slums. By shedding light on this specific locale, we seek to unravel the intertwined socio-economic challenges faced by the community and catalyze effective interventions. Continue reading
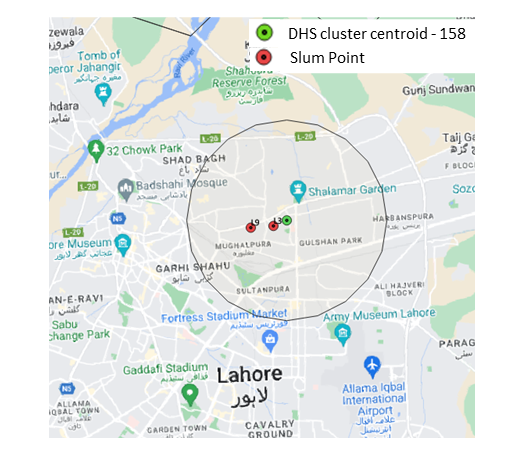
Our third blog in the series delves into the intricate network of poverty that engulfs this particular cluster and encompassed slums. It aims to provide an unprecedented perspective on the multifaceted issues of poverty within this area, with a focus on devising comprehensive strategies for poverty alleviation. Continue reading
This second blog in the series offers a rigorous exploration of poverty’s complex facets within Lahore’s Cluster ID 156 and encompassed slums. By shedding light on this specific locale, we seek to unravel the intertwined socio-economic challenges faced by the community and catalyze effective interventions. Continue reading
This paper develops the novel notion of deconstructive learning and proposes a practical model for deconstructing a broad class of binary classifiers commonly used in vision applications. Specifically, the problem studied in this paper is: Given an image-based binary classifier CC as a black-box oracle, how much can we learn of its internal working by simply querying it? In particular, we demonstrate that it is possible to ascertain the type of kernel function used by… Continue reading
With the recent breakthrough in commodity 3D imaging solutions such as depth sensing, photogrammetry, stereoscopic vision and structured light, 3D shape recognition is becoming an increasingly important problem. A longstanding question is what should be the format of the 3D shape (such as voxel, mesh, point-cloud etc.) and what could be a good generic feature representation for shape recognition. This question is particularly important in the context of convolutional neural network (CNN) whose efficacy and… Continue reading
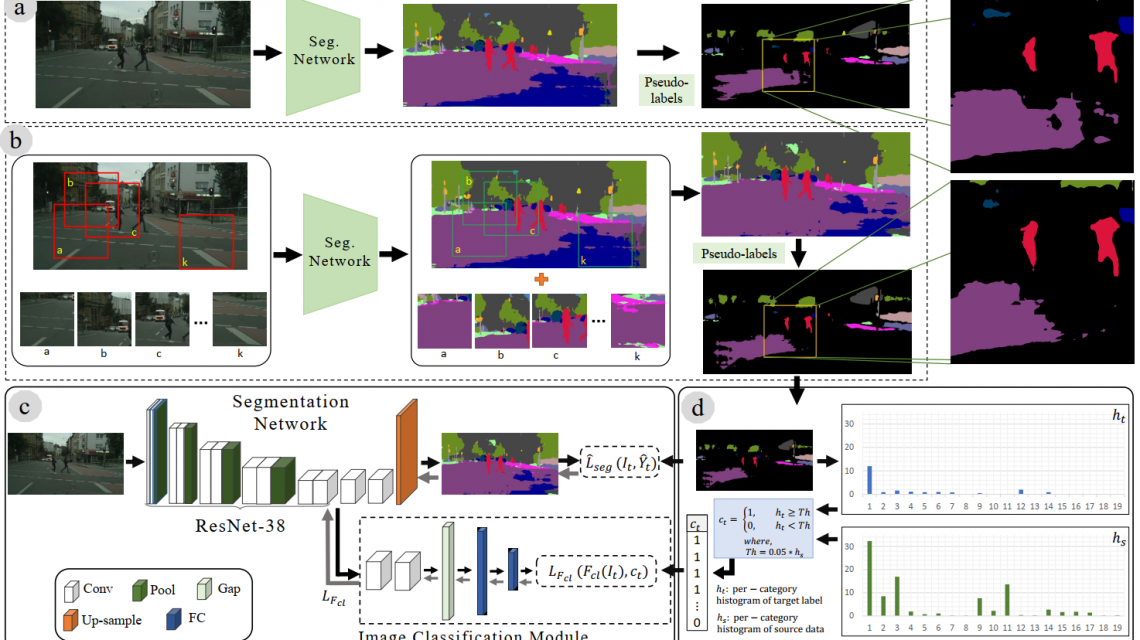
Most of the recent Deep Semantic Segmentation algorithms suffer from large generalization errors, even when powerful hierarchical representation models based on convolutional neural networks have been employed. This could be attributed to limited training data and large distribution gap in train and test domain datasets.In this paper, we propose a multi-level self-supervised learning model for domain adaptation of semantic segmentation.Exploiting the idea that an object (and most of the stuff given context) should be labeled… Continue reading
Local keypoint matching is an important step for computer vision based tasks. In recent years, Deep Convolutional Neural Network (CNN) based strategies have been employed to learn descriptor generation to enhance keypoint matching accuracy. Recent state-of-art works in this direction primarily rely upon a triplet based loss function (and its variations) utilizing three samples: an anchor, a positive and a negative. In this work we propose a novel “Twin Negative Mining” based sampling strategy coupled with… Continue reading
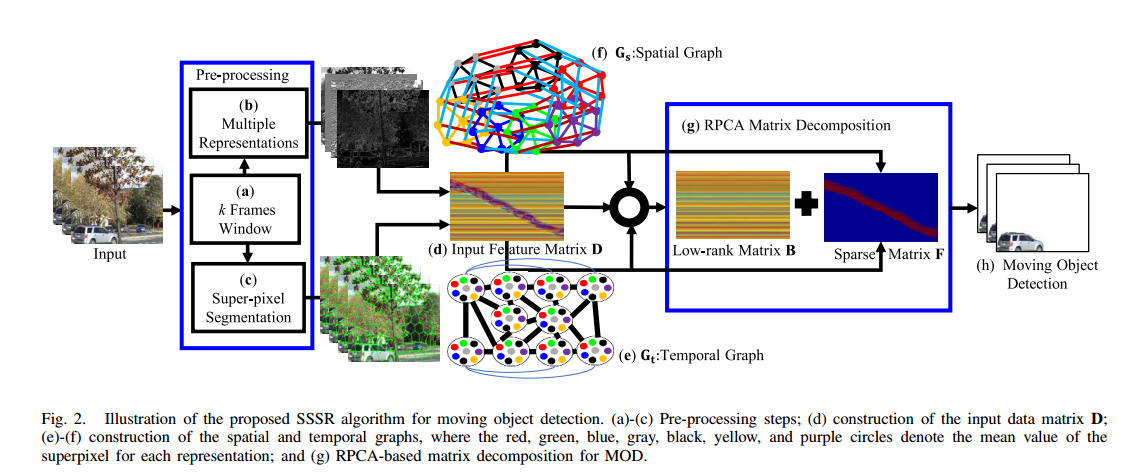
Moving object detection is a fundamental step in various computer vision applications. Robust principal component analysis (RPCA)-based methods have often been employed for this task. However, the performance of these methods deteriorates in the presence of dynamic background scenes, camera jitter, camouflaged moving objects, and/or variations in illumination. It is because of an underlying assumption that the elements in the sparse component are mutually independent, and thus the spatiotemporal structure of the moving objects is… Continue reading