Distribution regularized self-supervised learning for domain adaptation of semantic segmentation
(Published at Image and Vision Computing 2022)
(Published at Image and Vision Computing 2022)
Javed Iqbal1, Hamza Rawal1, Rehan Hafiz1, Yu-Tseh Chi2, Mohsen Ali1
1 Information Technology University, Pakistan 2 Facebook, Menlo Park, CA, USA
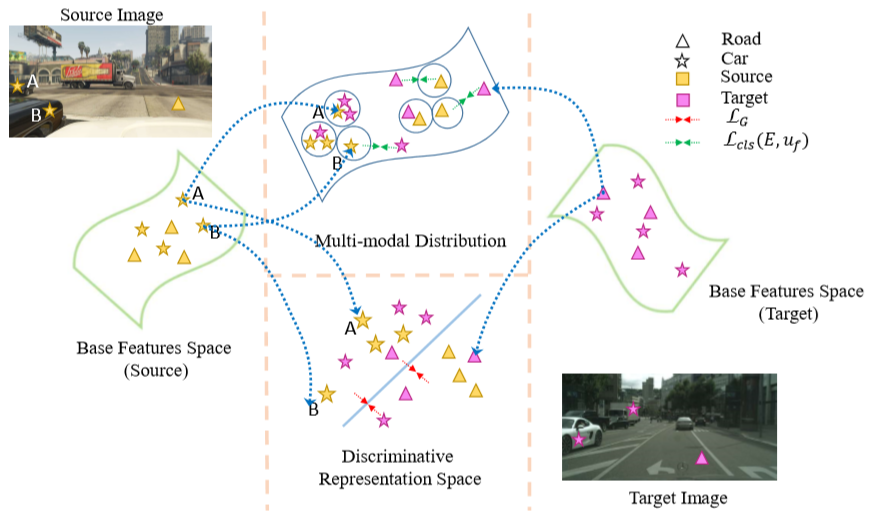
Figure 1: Separately capturing pixel-level intra-class variations and inter-class discriminative information, enables us to perform different alignment operations, i.e. class aware mode alignment & cross-entropy based decision boundary alignment. A & B are consistent in-term of being on same side of decision boundary, but variant enough to map to different modes.
This paper proposes a novel pixel-level distribution regularization scheme (DRSL) for self-supervised domain adaptation of semantic segmentation. In a typical setting, the classification loss forces the semantic segmentation model to greedily learn the representations that capture inter-class variations in order to determine the decision (class) boundary. Due to the domain-shift, this decision boundary is unaligned in the target domain, resulting in noisy pseudo labels adversely affecting self-supervised domain adaptation. To overcome this limitation, along with capturing inter-class variation, we capture pixel-level intra-class variations through class-aware multi-modal distribution learning (MMDL). Thus, the information necessary for capturing the intra-class variations is explicitly disentangled from the information necessary for inter-class discrimination. Features captured thus are much more informative, resulting in pseudo-labels with low noise. This disentanglement allows us to perform separate alignments in discriminative space and multi-modal distribution space, using cross-entropy based self-learning for former. For later, we propose novel stochastic mode alignment method, by explicitly decreasing the distance between the target and source pixels that map to the same mode. The distance metric learning loss, computed over pseudo-labels and backpropagated from multi-modal modeling head, acts as the regularizer over the base network shared with the segmentation head. The results from comprehensive experiments on synthetic to real domain adaptation setups, i.e., GTA-V/SYNTHIA to Cityscapes, show that DRSL outperforms many existing approaches (a minimum margin of 2.3% and 2.5% in mIoU for SYNTHIA to Cityscapes).
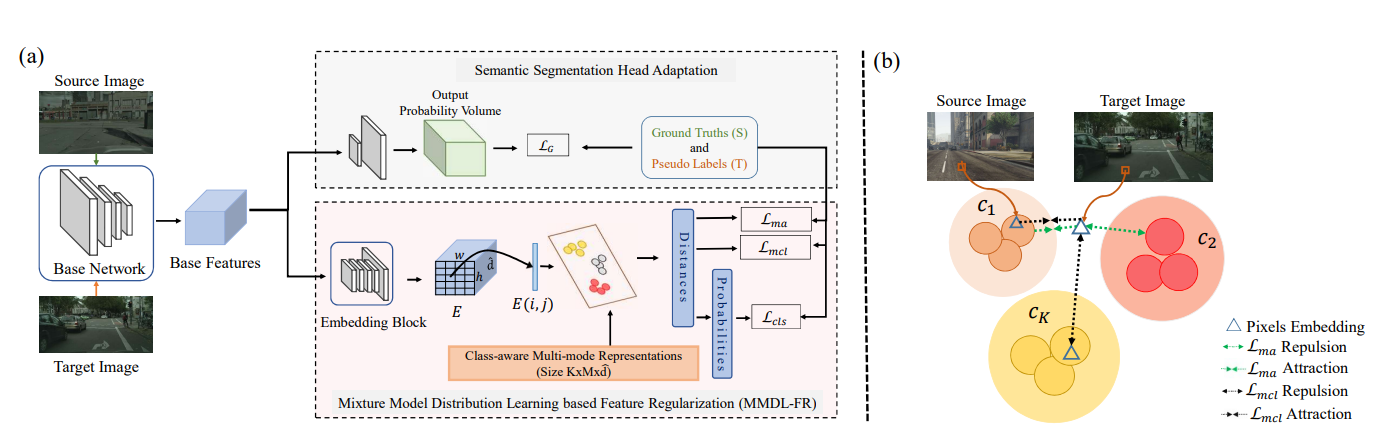
The proposed DRSL approach (a) Base features extracted from the base network are used for two separate tasks. The MMDL-FR module captures intra-class variations through multi-modal distribution learning. Semantic Segmentation head estimates the discriminative class boundaries necessary for the primary segmentation task. This disentanglement allows us simultaneous alignment in discriminative and multi-modal space, allowing MMDL-FR module to act as a regularizer over the Segmentation Head. (b) The proposed Stochastic mode alignment: Minimizing Lmcl brings the source and target embeddings of the same mode of the same class closer than any source pixel’s embedding belonging to different class. Lma decreases the in-mode variance for the target samples by forcing them to come closer to the assigned mode and move away from other class’s modes.
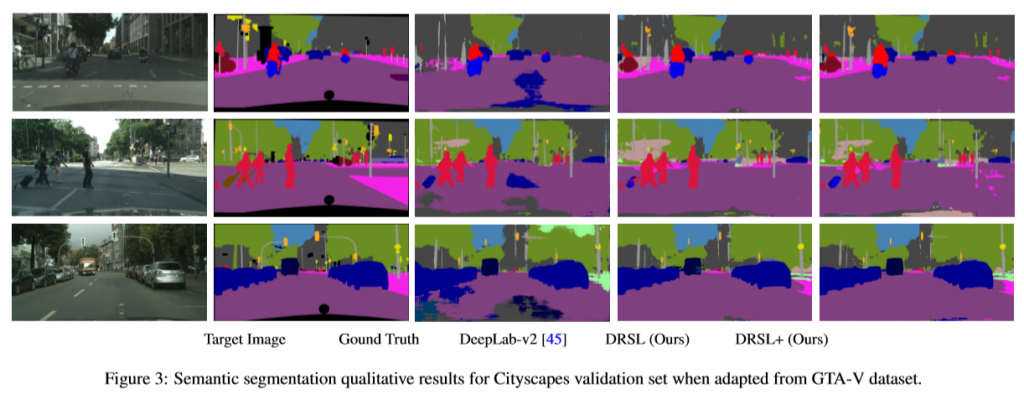
Click on image to view it
Javed Iqbal , PhD Student, Intelligent Machines Lab, ITU, Lahore, Pakistan
Email: javed.iqbal@itu.edu.pk
Web: linkedin
Hamza Rawal, Graduate Fellow, Intelligent Machines Lab, ITU, Lahore, Pakistan
Email: mscs18004@itu.edu.pk
Rehan Hafiz, Professor, Dept. of Computer Engineering, ITU Pakistan
Email: rehan.hafiz@itu.edu.pk
Web: https://im.itu.edu.pk/
Yu-TsehChi, Manager, 3D Computer Vision at Meta
Email: jchi@fb.com
Dr. Mohsen Ali, Assistant Professor, Intelligent Machines Lab, ITU, Lahore, Pakistan
Email: mohsen.ali@itu.edu.pk
Web: https://im.itu.edu.pk/
Iqbal, Javed, Hamza Rawal, Rehan Hafiz, Yu-Tseh Chi, and Mohsen Ali. “Distribution regularized self-supervised learning for domain adaptation of semantic segmentation.” Image and Vision Computing 124 (2022): 104504.