Local keypoint matching is an important step for computer vision based tasks. In recent years, Deep Convolutional Neural Network (CNN) based strategies have been employed to learn descriptor generation to enhance keypoint matching accuracy. Recent state-of-art works in this direction primarily rely upon a triplet based loss function (and its variations) utilizing three samples: an anchor, a positive and a negative. In this work we propose a novel “Twin Negative Mining” based sampling strategy coupled with… Continue reading
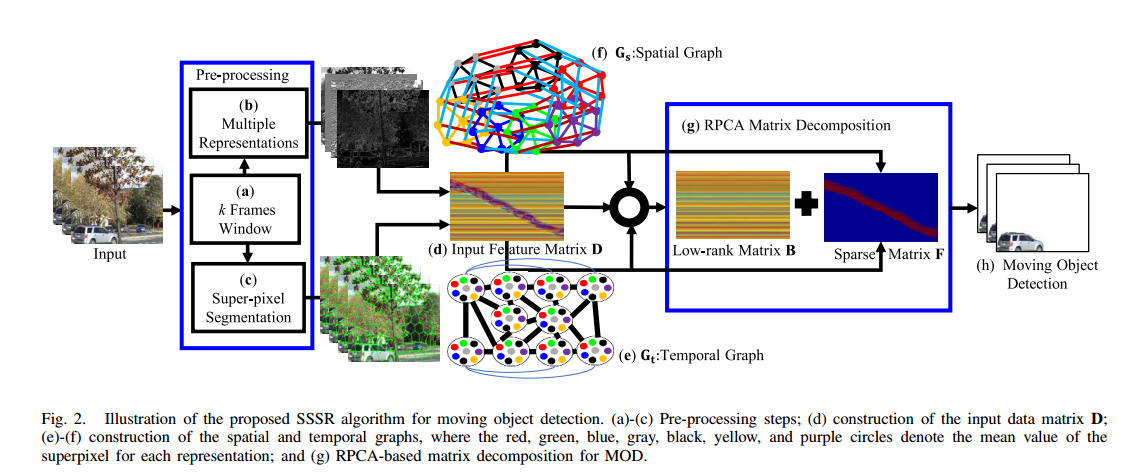
Moving object detection is a fundamental step in various computer vision applications. Robust principal component analysis (RPCA)-based methods have often been employed for this task. However, the performance of these methods deteriorates in the presence of dynamic background scenes, camera jitter, camouflaged moving objects, and/or variations in illumination. It is because of an underlying assumption that the elements in the sparse component are mutually independent, and thus the spatiotemporal structure of the moving objects is… Continue reading
Current image transformation and recoloring algorithms try to introduce artistic effect in the photographed images, based on users input of target image(s) or selection of pre-designed filters. In this paper we present an automatic image-transformation method that transforms the source image such that it induces an emotional affect on the viewer, as desired by the user. Our method can handle much more diverse set of images than previous methods. A discussion and reasoning of failure… Continue reading
Deep convolutional neural networks (CNNs) have outperformed existing object recognition and detection algorithms. This paper describes a deep learning approach that analyzes a geo-referenced satellite image and efficiently detects built structures in it. A Fully Convolutional Network (FCN) is trained on low-resolution Google earth satellite imagery in order to achieve the end result. The detected built communities are then correlated with the vaccination activity. ANZA SHAKEEL, MOHSEN ALI ARXIV 2017 Show More PDF Continue reading
This paper aims to bridge the affective gap between image content and the emotional response of the viewer, it elicits, by using High-Level Concepts (HLCs). In contrast to previous work that relied solely on low-level features or used convolutional neural network (CNN) as a blackbox, we use HLCs generated by pre-trained CNNs in an explicit way to investigate the relations/associations between these HLCs and a(small)set of Ekman’s emotional classes. Experimental results have demonstrated that our… Continue reading
Gunmen in a crowd is a challenging problem, that requires resolving the association of a person with an object (firearm). We present a novel approach to address this problem, by defining human-object interaction (and non-interaction) bounding boxes. In a given image, human and firearms are separately detected. Each detected human is paired with each detected firearm, allowing us to create a paired bounding box that contains both object and the human.A network is trained to… Continue reading
The existing approaches for salient motion segmentation are unable to explicitly learn geometric cues and often give false detections on prominent static objects. We exploit multiview geometric constraints to avoid such mistakes. To handle nonrigid background like sea, we also propose a robust fusion mechanism between motion and appearance-based features. We find dense trajectories, covering every pixel in the video, and propose trajectory-based epipolar distances to distinguish between background and foreground regions. Trajectory epipolar distances… Continue reading
Self-supervised learning approaches for unsupervised domain adaptation (UDA) of semantic segmentation models suffer from challenges of predicting and selecting reasonable good quality pseudo labels. In this paper, we propose a novel approach of exploiting scale-invariance property of the semantic segmentation model for self-supervised domain adaptation. Our algorithm is based on a reasonable assumption that, in general, regardless of the size of the object and stuff (given context) the semantic labeling should be unchanged. We show… Continue reading
ITU Faculty Wins Facebook’s CV4GC Research Award: Principal Investigator, Dr. Waqas Sultani, along with Co-Principal Investigators, Dr. Mohsen Ali and Dr. Arif Mehmood, have secured Facebook’s Computer Vision for Global Challenges (CV4GC) Research Award. It is an initiative to bring the computer vision community closer to socially impactful tasks, datasets and applications for worldwide impact. The application was selected for funding after a rigorous review process and among the more than 300 applications. PI and… Continue reading
Multi-focus image fusion has emerged as an important research area in information fusion. It aims at increasing the depth-of-field by extracting focused regions from multiple partially focused images, and merging them together to produce a composite image in which all objects are in focus. In this paper, a novel multi-focus image fusion algorithm is presented in which the task of detecting the focused regions is achieved using a Content Adaptive Blurring (CAB) algorithm. The proposed… Continue reading