Warning: preg_match(): Compilation failed: invalid range in character class at offset 12 in /home/u295156359/domains/itu.edu.pk/public_html/im/wp-content/plugins/js_composer/include/classes/shortcodes/vc-basic-grid.php on line 184
DECONSTRUCTING BINARY CLASSIFIERS IN COMPUTER VISION
This paper develops the novel notion of deconstructive learning and proposes a practical model for deconstructing a broad class of binary classifiers commonly used in vision applications. Specifically, the problem studied in this paper is: Given an image-based binary classifier CC as a black-box oracle, how much can we learn of its internal working by simply querying it? In particular, we demonstrate that it is possible to ascertain the type of kernel function used by…

MORE FOR LESS: INSIGHTS INTO CONVOLUTIONAL NETS FOR 3D POINT CLOUD RECOGNITION
With the recent breakthrough in commodity 3D imaging solutions such as depth sensing, photogrammetry, stereoscopic vision and structured light, 3D shape recognition is becoming an increasingly important problem. A longstanding question is what should be the format of the 3D shape (such as voxel, mesh, point-cloud etc.) and what could be a good generic feature representation for shape recognition. This question is particularly important in the context of convolutional neural network (CNN) whose efficacy and…
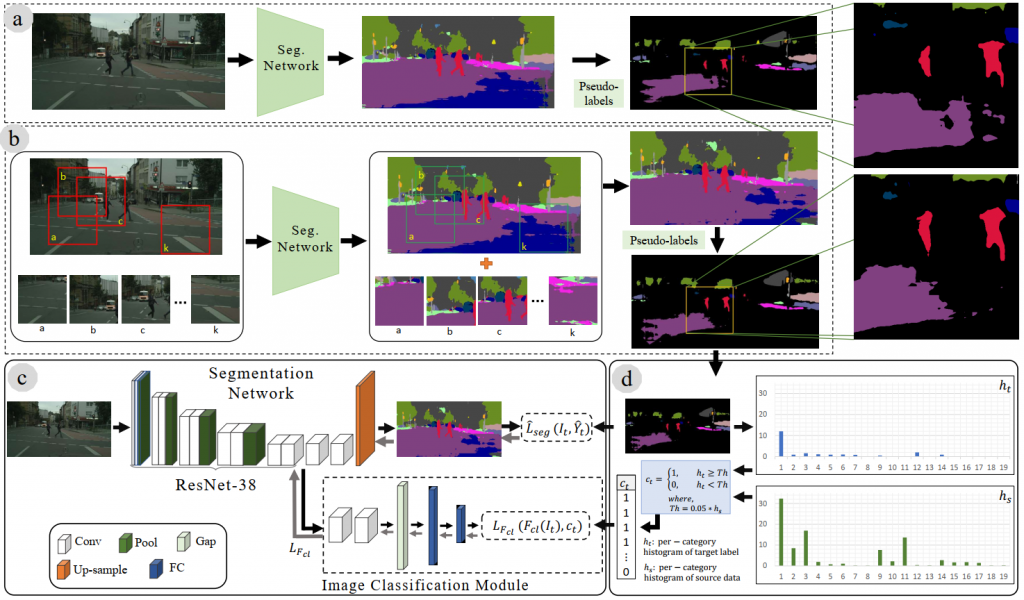
MLSL: MULTI-LEVEL SELF-SUPERVISED LEARNING FOR DOMAIN ADAPTATION WITH SPATIALLY INDEPENDENT AND SEMANTICALLY CONSISTENT LABELING
Most of the recent Deep Semantic Segmentation algorithms suffer from large generalization errors, even when powerful hierarchical representation models based on convolutional neural networks have been employed. This could be attributed to limited training data and large distribution gap in train and test domain datasets.In this paper, we propose a multi-level self-supervised learning model for domain adaptation of semantic segmentation.Exploiting the idea that an object (and most of the stuff given context) should be labeled…