WEAKLY-SUPERVISED DOMAIN ADAPTATION FOR BUILT-UP REGION SEGMENTATION IN AERIAL AND SATELLITE IMAGERY

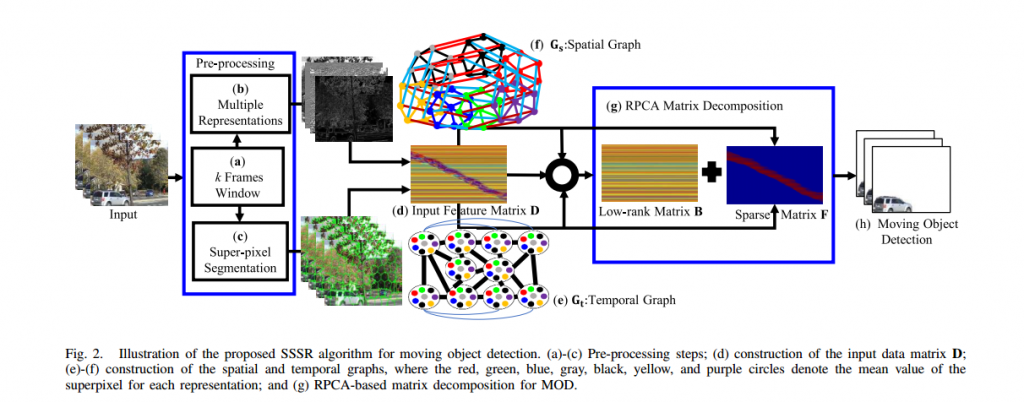
Built-up area estimation is an important component in understanding the human impact on the environment, effect of public policy and in general urban population analysis. The diverse nature of aerial and satellite imagery (capturing different geographical locations, terrains and weather conditions) and lack of labeled data covering this diversity makes machine learning algorithms difficult to generalize for such tasks, especially across multiple domains. Re-training for new domain is both computationally and labor expansive mainly due to the cost of collecting pixel level labels required for the segmentation task. Domain adaptation algorithms have been proposed to enable algorithms trained on images of one domain (source) to work on images from other dataset (target). Unsupervised domain adapta- tion is a popular choice since it allows the trained model to adapt without requiring any ground-truth information of the target domain. On the other hand, due to the lack of strong spatial context and structure, in comparison to the ground imagery, application of existing unsupervised domain adaptation methods results in the sub-optimal adap- tation. We thoroughly study limitations of existing domain adaptation methods and propose a weakly-supervised adaptation strategy where we assume image level labels are available for the target domain. More specifically, we design a built-up area seg- mentation network (as encoder-decoder), with image classification head added to guide the adaptation. The devised system is able to address the problem of visual differences in multiple satellite and aerial imagery datasets, ranging from high resolution (HR) to very high resolution (VHR), by investigating the latent space as well as the structured output space.
A realistic and challenging HR dataset is created by hand-tagging the 73.4 sq-km of Rwanda, capturing a variety of build-up structures over different terrain. The devel- oped dataset is spatially rich compared to existing datasets and covers diverse built-up scenarios including built-up areas in forests and deserts, mud houses, tin and colored rooftops. Extensive experiments are performed by adapting from the single-source domain datasets, such as Massachusetts Buildings Dataset, to segment out the target domain. We achieve high gains ranging 11.6%-52% in IoU over the existing state-of- the-art methods.

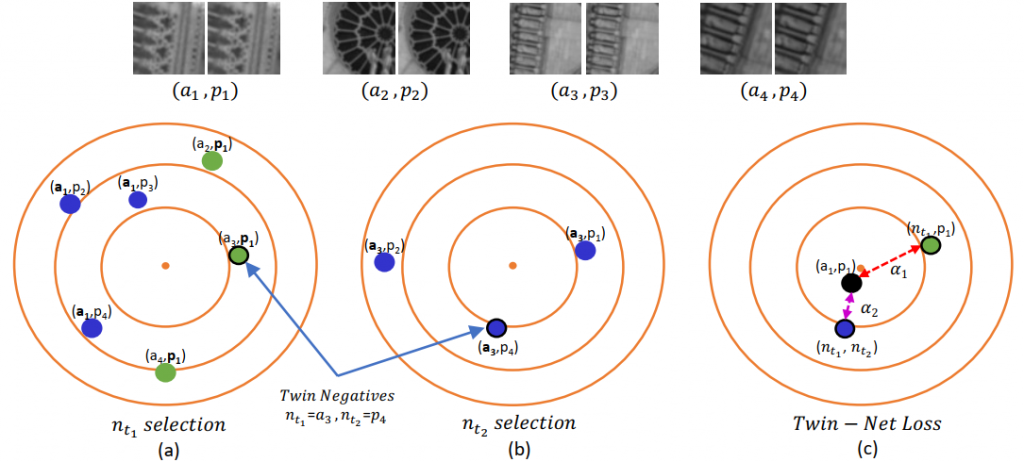
 Self-supervisedlearningapproachesforunsuperviseddomain adaptation (UDA) of semantic segmentation models suffer from chal- lenges of predicting and selecting reasonable good quality pseudo labels. In this paper, we propose a novel approach of exploiting scale-invariance property of the semantic segmentation model for self-supervised domain adaptation. Our algorithm is based on a reasonable assumption that, in general, regardless of the size of the object and stuff (given context) the semantic labeling should be unchanged. We show that this constraint is violated over the images of the target domain, and hence could be used to transfer labels in-between differently scaled patches. Specifically, we show that semantic segmentation model produces output with high entropy when presented with scaled-up patches of target domain, in comparison to when presented original size images. These scale-invariant examples are extracted from the most confident images of the target domain. Dy- namic class specific entropy thresholding mechanism is presented to filter out unreliable pseudo-labels. Furthermore, we also incorporate the focal loss to tackle the problem of class imbalance in self-supervised learn- ing. Extensive experiments have been performed, and results indicate that exploiting the scale-invariant labeling, we outperform existing self- supervised based state-of-the-art domain adaptation methods. Specifi- cally, we achieve 1.3% and 3.8% of lead for GTA5 to Cityscapes and SYNTHIA to Cityscapes with VGG16-FCN8 baseline network.
Self-supervisedlearningapproachesforunsuperviseddomain adaptation (UDA) of semantic segmentation models suffer from chal- lenges of predicting and selecting reasonable good quality pseudo labels. In this paper, we propose a novel approach of exploiting scale-invariance property of the semantic segmentation model for self-supervised domain adaptation. Our algorithm is based on a reasonable assumption that, in general, regardless of the size of the object and stuff (given context) the semantic labeling should be unchanged. We show that this constraint is violated over the images of the target domain, and hence could be used to transfer labels in-between differently scaled patches. Specifically, we show that semantic segmentation model produces output with high entropy when presented with scaled-up patches of target domain, in comparison to when presented original size images. These scale-invariant examples are extracted from the most confident images of the target domain. Dy- namic class specific entropy thresholding mechanism is presented to filter out unreliable pseudo-labels. Furthermore, we also incorporate the focal loss to tackle the problem of class imbalance in self-supervised learn- ing. Extensive experiments have been performed, and results indicate that exploiting the scale-invariant labeling, we outperform existing self- supervised based state-of-the-art domain adaptation methods. Specifi- cally, we achieve 1.3% and 3.8% of lead for GTA5 to Cityscapes and SYNTHIA to Cityscapes with VGG16-FCN8 baseline network.