
Figure: An illustration on which detections will be considered as pseudo-labels and which for extracting tiles. More certain detections, such as pedestrians are taken as pseudo-labels, whereas relatively uncertain ones, like cars under fog, are used for extracting tiles.
Method (Extended)
Revisiting uncertainty quantification
We note that previous work relies on averaged class confidences as a surrogate measure of detection model uncertainty in its class assignment and object localization. It doesn’t take into account the spread of the distribution, and so could be misleading for predictions with relatively greater localization uncertainty. To this end, we revisit the uncertainty quantification and introduce variance across class confidences with the averaged class confidences. Since the variance across class confidences is a much better estimate of the predictive uncertainty, using them in conjunction with averaged class confidences will allow us to further improve the synergy between self-training and adversarial alignment through facilitating more accurate pseudo-labeling and informed tiling.
Uncertainty-guided pseudo-labeling with a new constraint
Previous work selects pseudo-labels using averaged class confidences as uncertainty measure and detection consistency for self-training. This allows us to choose accurate pseudo-labels over sole confidence-based criterion, which is crucial for effective adaptation and also improves model calibration under domain shift. To further improve the selection of pseudo-labels, we propose to use average class confidences and variance across class confidences as the model’s detection uncertainty along with the detection consistency
Uncertainty-guided tiling with extended set
In previous work, the detected regions with certain criteria are used to extract tiles for adversarial learning. We observe that the regions that fail the uncertainty constraint but satisfy the detection consistency constraint were not utilized for extracting tiles. This rather limits the space of uncertain detections (possibly containing some object information) that can be potentially exploited for enhanced adversarial alignment. Formally, we choose a region for extracting a tile that fulfills the following criteria. Further, along with the extracted tiles, we also randomly sample the full image in the mini-batch to extend scale information.
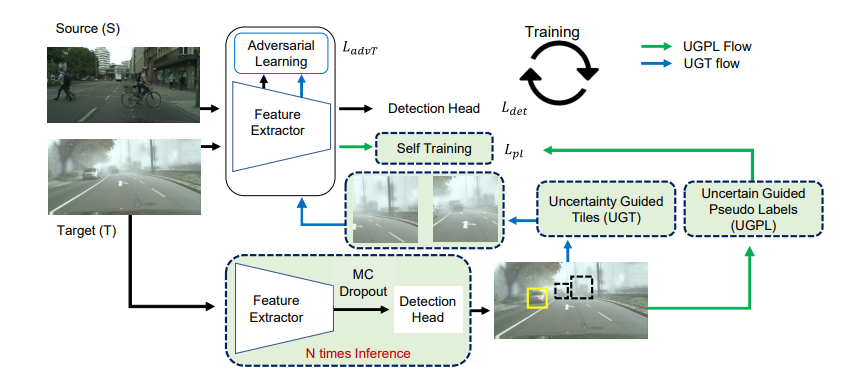
Figure: Overall architecture of our method. Fundamentally, it is a one-stage detector with an adversarial feature alignment stage. We propose uncertainty-guided self training with pseudo-labels (UGPL) and uncertainty-guided adversarial alignment via tiling (UGT) (in dotted boxes). UGPL produces accurate pseudo-labels in target image which are used in tandem with ground-truth labels in source image for training. UGT extracts tiles around possibly object-like regions in target image which are used with randomly extracted tiles around ground-truth labels in source domain for adversarial feature alignment.
Qualitative Results

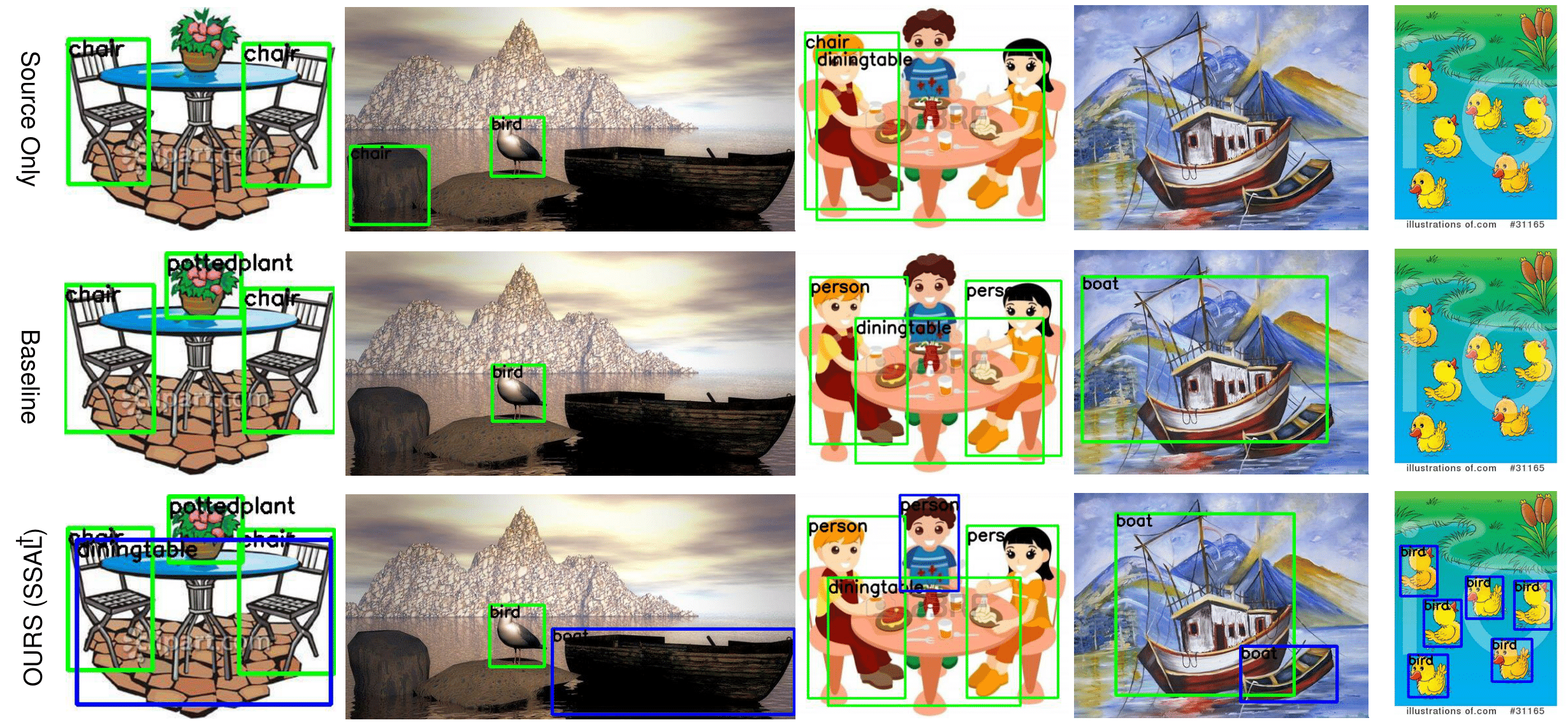
Detections missed by the baseline and found by our method (extended) are shown in Blue. Our method detects more number of objects under large domain shift compared to EPM.